
Introduction
In one of my previous posts I illustrated how to perform R analysis using a Spark cluster. This is all safe and sound if the developer is starting from scratch and/or no existing, proven, R scripts are already developed. But most (data)scientists already have a handful of scripts that they use during their day-to-day work and need some extra power around them. Or, even better, the developed models are to be used during the actual realtime processing of the data, for instance to support a recommendation engine or some other complex analysis.
In this post I’ll illustrate a hybrid solution leveraging the power of both Spark (by which I mean in this post Spark/Scala) and R but this time using a powerful feature called ‘piping’. RDD’s have the ability to pipe themselves out of the Spark context using regular standard-in (stdin) and standard-out (stdout). This behavior closely resamples the ability of map/reduce to use Python, Perl, Bash or other scripts to do mapping or reducing.
Once you get to know how to actually do it, it’s surprisingly simple!
Setup
A proper R environment is required, for which the setup can be found in one of my previous posts. Note that to follow along this particular post, you will not need RStudio, but it will come in handy if you like to extend the scripts provided. You will however need a couple of extra packages (text mining, NLP and snowball stemmer). Start R and issue the following commands:
install.packages(‘tm’, repos=’http://cran.xl-mirror.nl’)
install.packages(‘NLP’, repos=’http://cran.xl-mirror.nl’)
install.packages(‘SnowballC’, repos=’http://cran.xl-mirror.nl’)
You may now quit the R session by invoking
q()
See the screenshot below for full details of the output.

Let’s go!
In the example below, the responsibilities of R and Spark are clearly separated:
- R is used only to sanitize the incoming data
- Spark performs the actual wordcount
The picture below represents the dataflow. Once the Spark context is started up, it starts reading a file called ‘alice.txt’. Every line is piped-out on stdout to a R wrapper script containing only logic to read the lines, pass them to a function called ‘sanitize’ (which is loaded from the corresponding R file) and return them on stdout of the R Runtime to the Spark context.
Using a wrapper keeps the code in sanitize.R reusable and independent on being called just from Spark. In this case, a simple ‘source’ command is executed to load the function in sanitize.R; in productional environments it may be wise to create reusable and easily distributable packages contained in a repository.
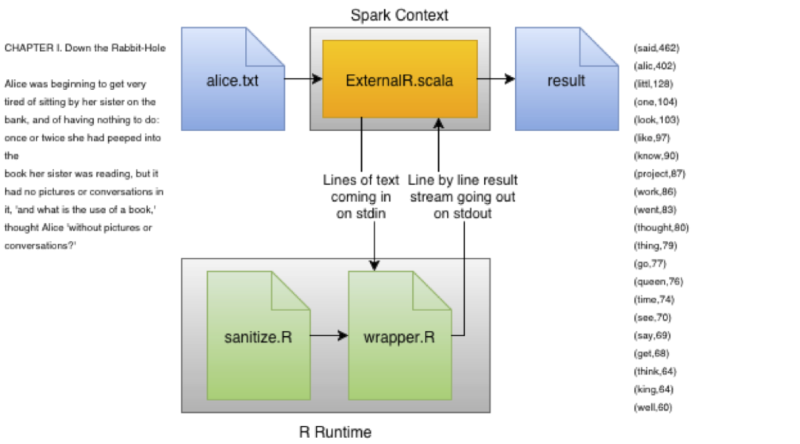
The Scala context picks up the sanitized lines and uses map and reduce logic to calculate the appearances of the words. These will probably differ from the original input because, for instance, stemming is done (note the appearance of the word ‘alic’ in stead of the original input ‘Alice’. Finally, the result is written to stdout.
Let’s start with the Scala code. Only relevant code is shown for brevity. Also, the code below is a functional one-liner without any intermediate variables, hereby making it slightly less readable for a programmer to actually ‘get’ what’s happening.
File : ExternalR.scala

The comments in the code actually describe what’s taking place. After the SparkContext has been created, a textfile called ‘alice.txt’ is read using the ‘textFile’ method of the context and it’s contents piped to stdout using RDD’s ‘pipe’ function. In this particular case, the receiving end is an R script, but it may be any script or application which is able to read data from stdin and write to stdout.
The script or application that is called must be executable. On a Linux box that means it’s permissions are at least 500, to be executable and readible by the user that is executing the Scala code. If it’s not, an error will be raised:
java.io.IOException: Cannot run program “./wrapper.R”: error=13, Permission denied
After the R script returns it’s data the ‘classic’ wordcount is done. A few tricks have been added, for instance sorting the set on count (which implies doing a dual swap because there is nog sortByValue at the moment) and filtering empty words. Finally, the top 100 words are taken and output to the console.
Note that the above construction creates a scalable solution both from the Spark as well as the R perspective. As long as the R scripts does not need ALL the data from the input file, execution of the R script will scale linearly (within the boundaries of your cluster, that is). The Spark context will collect all data together and reduce the data to it’s final state.
The R code is made of two scripts,explained below.
File : wrapper.R

Again, the code above is pretty self-explanatory. First, a check is done if the requested function (sanitize) exists and, if not, the script containing it (sanitize.R ) is included. Stdin is opened, followed by reading it one line at the time (note the ‘n=1’ parameter to readLines). The line is passed to the sanitize function and it’s output written to stdout. Finally, stdin is closed. No return value is needed. The sha-bang (#!) at the head of the R script tells the system that this file is a set of commands to be fed to the command interpreter indicated. In this case, R. Without this sha-bang line, execution will most likely fail.
As said, the wrapper is called using two parameters, the library file to be loaded and the function to be called inside that library file, hereby creating a very versatile wrapper (not only for Spark) which can read from stdin, perform some logic, and write to stdout. A small performance penalty may be hit using the ‘eval’ construct. That has not been validated. Some example output from calling the wrapper standalone follows:

The wrapper may be extended to be able to include multiple libraries and function flows, but that exercise is left to the reader. The actual ‘business logic’ is done in sanitize.R. Needed libraries are loaded and the input line is sanitized according to our needs. The beauty of this is, this function may be part of a much bigger R library which has no clue that it will be called from a Spark context one day.
File : sanitize.R

Succesfully running the Spark/Scala job will result in something like the following screen, which can be found at http://localhost:4040 (or at the location of your Spark Driver host):

Summary
As said, leveraging the power of R from Spark is a breeze. It took me a little while to get it up and running, but the result is a scalable, generic solution to enable data scientist to have their R code being used from a Spark Context.