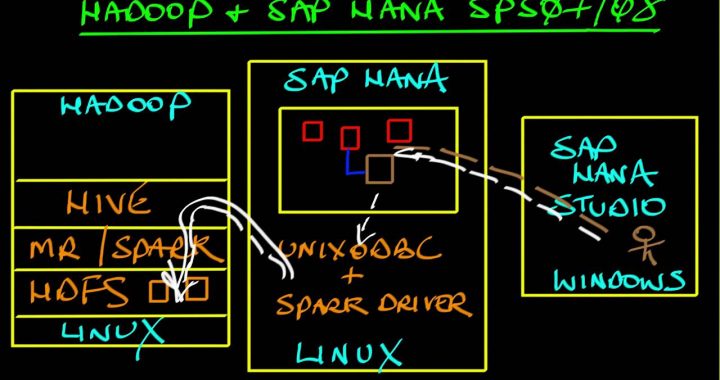
© Notice: I copied this post’s image from one of SAP’s Bob tutorials!
The Challenge
At one of my customers we need to install the SAP Spark Controller to be able to connect our MapR cluster to HANA. If you arrived at this post, you will know why this is a great feature for a lot of use cases. But it also lead to a small challenge which may be clear from the URL’s below:
- http://maprdocs.mapr.com/home/EcosystemRN/MEP3.0PkgNames.html
- https://uacp2.hana.ondemand.com/viewer/3b120d20f0b54c91a3be763d387e61ac/2.0.0.0/en-US/
In short: the 2.2.0 Spark Controller needs Spark 1.6 but MapR MEP3 provides Spark 2.1. Trust me, I have tried to get it running but due to the absence of the Spark assembly in 2.x versions and the absence of Akka stuff I think it’s nearly impossible to get it running unless SAP does a recompile. Luckily, in YARN, a Spark Job actually is ‘just another job’ if you just provide the Spark assembly when submitting. Because of this, you are still able to set up the Spark Controller while not having to hack too much and leave the cluster messy…. By far!
A few words of warning and a prerequisite
- Because I like to install things at minimum, sometimes I cut corners or use a different approach than stated in the fine manuals. This may lead to situations that are unsupported by one or the other vendor. This goes in particular for the installation of the Spark Controller, for which I didn’t use the rpm command to install, but extracted the rpm and copied the files over. I did this to be easily be able to switch between Spark Controller versions. In a production environment, nothing stops you from using the normal rpm installation approach
- With regards to MapR, I download one rpm from their repository to be able to extract just the jar file you need, no more. This prevents a full Spark installation having to be hanging around on your node(s)
- You will need a MapR 5.2 based cluster with MEP 3.0.1 installed. I will not cover the installation of that
Actions to be performed as root
I upgraded my old MEP 1.1 to MEP 3.0.1 using yum -y update (after changing /etc/yum.repos.d/mapr_ecosystem.repo to reflect the base url to be http://package.mapr.com/releases/MEP/MEP-3.0.1/redhat), but it seemed that this upgrade left my YARN installation unusable. To fix, I had to restore the rights on the container-executor executable as follows:
chmod -R 6050 /opt/mapr/hadoop/hadoop-2.7.0/bin/container-executor chown root.mapr /opt/mapr/hadoop/hadoop-2.7.0/bin/container-executor
From this point on it’s a straightforward install from the downloaded zip file at the SAP download site. Most of the comments will be in the code blocks.
# Add hanaes user and groups
# Note that it MUST be hanaes because it seems to be hardcoded in the jar's
groupadd sapsys
useradd -g sapsys -d /home/hanaes -s /bin/bash hanaes
# Create some directories we need. These are the default when you use rpm to install the controller
# You are able to change all of these but then you'll have to configure much more later on
mkdir -p /var/log/hanaes/ /var/run/hanaes/ /usr/sap/spark/
# Extract installation rpm from the 2.2.0 Spark Controller
unzip HANASPARKCTRL02_0-70002101.zip sap.hana.spark.controller-2.2.0-1.noarch.rpm
rpm2cpio sap.hana.spark.controller-2.2.0-1.noarch.rpm|cpio -idmv
# Now remove (be careful if you have an install present!) a possibly existing installation
rm -rf /usr/sap/spark/controller
# Move the extracted files to the target directory
mv usr/sap/spark/controller/ /usr/sap/spark/
# I remove this template because I do not want it to be interfering in any way with the installation
rm -f /usr/sap/spark/controller/conf/hanaes-template.xml
# Now the 'old' mapr-spark package rpm package is downloaded and the assembly jar we need extracted
wget http://archive.mapr.com/releases/MEP/MEP-1.1/redhat/mapr-spark-1.6.1.201707241448-1.noarch.rpm
mkdir -p ./opt/mapr/spark/spark-1.6.1/lib/
# The below command leaves us with the assembly in ./opt/mapr/spark/spark-1.6.1/lib/
rpm2cpio mapr-spark-1.6.1.201707241448-1.noarch.rpm| cpio -icv "*spark-assembly-1.6.1-mapr-1707-hadoop2.7.0-mapr-1602.jar"
# Remove possibly present old jars from Hive or Spark.
# We need fresh copies from the /opt/mapr/hive directory and the extracted rpm file
rm -f /usr/sap/spark/controller/lib/spark-assembly*jar /usr/sap/spark/controller/lib/datanucleus-*.jar /usr/sap/spark/controller/lib/bonecp-*.jar
# Copy needed files to lib dir of the Spark Controller installation
# Because the controller uses Hive as the metadata provider, these libs are needed to access the Hive Thrift Server
# (as per Spark Controller installation instructions)
cp /opt/mapr/hive/hive-2.1/lib/datanucleus-*.jar /opt/mapr/hive/hive-2.1/lib/bonecp-*.jar ./opt/mapr/spark/spark-1.6.1/lib/spark-assembly-1.6.1-mapr-1707-hadoop2.7.0-mapr-1602.jar /usr/sap/spark/controller/lib/
# Set ownership of files needed for hanaes
chown -R hanaes.sapsys /var/log/hanaes/ /var/run/hanaes/ /usr/sap/spark
# Make directory on HDFS for hanaes user, mostly to be able to stage the application to YARN
hadoop fs -mkdir -p /user/hanaes
hadoop fs -chown hanaes:sapsys /user/hanaes
# Now allow the hanaes user to actually submit an app to YARN. Add the below:
vi /opt/mapr/hadoop/hadoop-2.7.0/etc/hadoop/core-site.xml
<property>
<name>hadoop.proxyuser.hanaes.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hanaes.groups</name>
<value>*</value>
</property>
# You might need to tweak values like yarn.nodemanager.resource.memory-mb, but I'll leave that to the reader.
# Restart node- and resourcemanager to reflect the change above
maprcli node services resourcemanager restart -nodes <your cluster nodes with resource managers>
maprcli node services nodemanager restart -nodes <your cluster nodes with node managers>
Actions to be performed as the hanaes user
Once the root part is done, the hanaes user is able to configure the controller and start it. Most important part is the configuration part. Pay attention especially to location of the java home directory stored in the JAVA_HOME parameter. This will for sure be different on your install.
# Become hanaes
su - hanaes
# Configure Spark Controller
cd /usr/sap/spark/controller/conf/
# Contents of log4j.properties. This may be too chatty in production, you may restrict the rootCategory INFO to WARN or ERROR
# The INFO in the spark.sql packages will log the SQL executed and requested, which may come in handy when looking for errors.
log4j.rootCategory=INFO, console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n
log4j.logger.com.sap=INFO
log4j.logger.org.apache.spark.sql.hana=INFO
log4j.logger.org.apache.spark.sql.hive.hana=INFO
# Contents of hana_hadoop-env.sh. These are the bare minimum lines you will need to get started on MapR
#!/bin/bash
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.141-1.b16.el7_3.x86_64/
export HANA_SPARK_ASSEMBLY_JAR=/usr/sap/spark/controller/lib/spark-assembly-1.6.1-mapr-1707-hadoop2.7.0-mapr-1602.jar
export HADOOP_CONF_DIR=/opt/mapr/hadoop/hadoop-2.7.0/etc/hadoop/
export HADOOP_CLASSPATH=`hadoop classpath`
export HIVE_CONF_DIR=/opt/mapr/hive/hive-2.1/conf
# Contents of hanaes-site.xml. Tweak to your need, especially the executor instances and memory
# The below is for my one node testing VM
<?xml version="1.0"?>
<configuration>
<property>
<name>sap.hana.es.server.port</name>
<value>7860</value>
</property>
<property>
<name>spark.executor.memory</name>
<value>1g</value>
</property>
<property>
<name>spark.executor.instances</name>
<value>1</value>
</property>
<property>
<name>spark.executor.cores</name>
<value>1</value>
</property>
<property>
<name>sap.hana.enable.compression</name>
<value>true</value>
</property>
</configuration>
cd ../bin/
# If you are on a memory restricted node, you might want to change the ES_HEAPSIZE
# This got me baffeled for a while when using this latest Spark Controller version
# Main but undescriptive error I got was something like network.Server did not start, check YARN logs.
# But the driver did not start, so there was nothing in YARN ;)
vi hanaes (first line after the shebang line)
export HANA_ES_HEAPSIZE=2048
# I think you WILL need the large amount of memory if you want to use the caching feature but I'm not too sure about that.
# Now start the controller and cross your fingers
# I like to clear the log first when setting this up. In production situations this may not be handy.
echo > /var/log/hanaes/hana_controller.log && ./hanaes restart
# And monitor
tail -f /var/log/hanaes/hana_controller.log
The result
Well, that wasn’t too hard! Spark Controller is up and running and accessible from HANA Studio.
[hanaes@mapr ~]$ cat /var/log/hanaes/hana_controller.log
17/08/17 12:18:00 INFO Server: Starting Spark Controller
17/08/17 12:18:02 INFO CommandRouter$$anon$1: Added JAR /usr/sap/spark/controller/lib/controller.common-2.1.1.jar at ...
17/08/17 12:18:02 INFO CommandRouter$$anon$1: Added JAR /usr/sap/spark/controller/lib/spark1_6/spark.shims_1.6.2-2.1.1.jar at ...
17/08/17 12:18:02 INFO CommandRouter$$anon$1: Added JAR /usr/sap/spark/controller/lib/controller.core-2.1.1.jar at ...
17/08/17 12:18:02 INFO ZooKeeper: Client environment:java.class.path=/usr/sap/spark/controller/lib/spark-assembly-1.6.1-mapr-1707-hadoop2.7.0-mapr-1602.jar: ...
17/08/17 12:18:03 INFO Client: Uploading resource file:/usr/sap/spark/controller/lib/spark-assembly-1.6.1-mapr-1707-hadoop2.7.0-mapr-1602.jar -> maprfs:/...
17/08/17 12:18:03 INFO Client: Uploading resource file:/usr/sap/spark/controller/lib/spark.extension-2.1.1.jar -> maprfs:/...
17/08/17 12:18:03 INFO Client: Uploading resource file:/usr/sap/spark/controller/lib/controller.common-2.1.1.jar -> maprfs:/...
17/08/17 12:18:10 INFO CommandRouterDefault: Running Spark Controller on Spark 1.6.1 with Application Id application_1502967355788_0022
17/08/17 12:18:10 INFO CommandRouterDefault: Connecting to Hive MetaStore!
17/08/17 12:18:11 INFO HanaHiveSQLContext: Initializing execution hive, version 1.2.1
17/08/17 12:18:17 WARN ObjectStore: Version information not found in metastore. hive.metastore.schema.verification is not enabled so recording the schema version 1.2.0
17/08/17 12:18:18 INFO HanaHiveSQLContext: Initializing HiveMetastoreConnection version 1.2.1 using Spark classes.
17/08/17 12:18:18 INFO metastore: Trying to connect to metastore with URI thrift://mapr.whizzkit.nl:9083
17/08/17 12:18:18 INFO metastore: Connected to metastore.
17/08/17 12:18:18 INFO CommandRouterDefault: Server started
[root@mapr ~]# yarn application -list
17/08/17 15:44:58 INFO client.MapRZKBasedRMFailoverProxyProvider: Updated RM address to mapr.whizzkit.nl/10.80.91.143:8032
Total number of applications (application-types: [] and states: [SUBMITTED, ACCEPTED, RUNNING]):1
Application-Id Application-Name Application-Type User Queue State Final-State Progress Tracking-URL
application_1502967355788_0022 SAP HANA Spark Controller:sparksql SPARK hanaes root.hanaes RUNNING UNDEFINED 10% http://mapr.whizzkit.nl:4040
Have fun installing!