
Introduction
So here you find yourself with a shiny new smartcard which enables you to log in to the client’s network. The IT guys did a great job setting up your corporate laptop, you happen to be a local admin on it, and you are dying to start the installation of your preferred Hadoop distribution and run al those fancy Spark jobs the data scientist made. It’s still your first day, so naively you ask one of your co-workers the ip address and credentials for one of the vm’s the (other) IT guys have prepared for you.
BUMP…
See that smartcard you got? That’s your ticket to cluster heaven. Never forget to bring it with you, or your day will be worthless. Not also does it unlock your laptop, the security infrastructure this company has laid down forbids local users on servers and relies on the use of Kerberos tickets. I’m by far an expert on that matter, so I will stick to saying that this was working without a flaw (but it’s important later on). Ah, another challenge… Root access on the vm’s? No way, José.
So what about the ip addresses of the cluster’s servers, you ask. Wait a minute here, sparky. You find yourself at a pretty large company with all kinds of sensitive customer information. The cluster’s vm’s are only to be accessed using a stepping server, giving IT the possibility to lock you out of ALL vm’s at once if you misbehave. Slowly you get the feeling that one day to install your cluster will possibly not suffice. Because of the lack of root privileges and the minimum amount of needed cluster components, I decided to do a plain Apache Hadoop install in stead of that wonderful all-open-source distribution with the light green logo.
IT provided me with a dedicated user called ‘cluster’ which I was able to sudo to. This user became the owner of all software beneath the /opt/cluster directory. For the sake if simplicity I assume in this article that this user starts all processes, in stead of dedicated users for HDFS, YARN, Elasticsearch and Kibana (which is preferred). The installation of the components is out of scope of this article.
Let’s go
I decided that for the moment I would be happy if all frontend web ui’s (f.i. HDFS, YARN, Spark Drivers and Kibana) would be accessible from my laptop. During an earlier project I struggled to submit Spark jobs using SSH forwarding, so I set that wish aside. Enough hurdles ahead, but I never fear to take them. So let me first introduce the global picture.
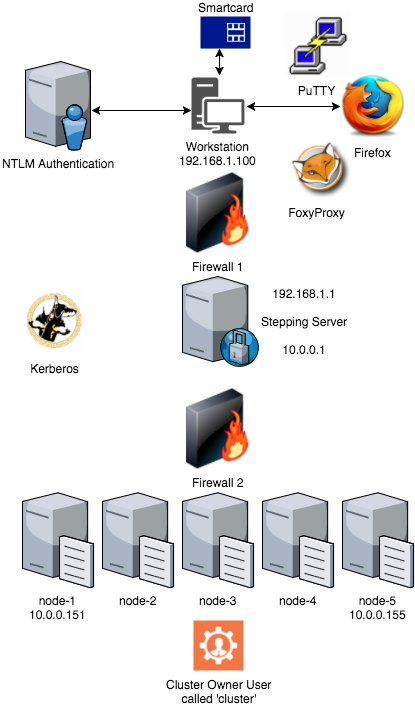
There is a office LAN in the 192.168.x.x range with a DNS server that serves requests for that LAN only. You are authenticated on your (Windows) workstation using a smartcard which will give you a Kerberos ticket via NTLM to access servers on the complete network. Access to the cluster LAN in the 10.0.0.x range is via the dual headed Stepping Server. Your workstation holds Firefox, PuTTY and the FoxyProxy plugin. IT has granted you access to the Stepping Server and the nodes of the cluster. Inter-cluster-node fire-walling is turned OFF for simplicity. (There are already two in front of the cluster, right?)
So the basic challenges listed:
- Securely access the web ui’s on the cluster nodes from the workstation
- Access the nodes by hostname
- Respect the Kerberos infrastructure
- Prevent exposure of those ui’s and data to other users
- Don’t do illegal things. I repeat: do not do illegal things
Before you continue to do this yourself, a few assumptions are made
- You are able to edit the hosts file on your machine (which needs root in Unix-like systems and administrator rights on Windows) For another client a actually wrote a Java program which is able to use a non-root private DNS server, which I may write another article on in the future
- You are able to install Firefox plugins (if bullet 1 above is not possible, there might by Firefox plugins that can overrule or add DNS records, I have not taken a look into that)
- On the stepping server, SSH forwarding is allowed. This may seem trivial, but some IT departments might disable this feature to actually prevent you from doing what I am about to show to you.
- You are comfortable with a state of mind that is summarised as ‘if it’s possible, it’s allowed’. But remember bullet 5 above!
DNS resolving
This is actually one of the easiest bits. Just edit your hosts file (c:\windows\system32\drivers\etc\hosts on Windows or /etc/hosts on most Unix-like systems) to include
10 . 0 . 0 . 151 node-1 10 . 0 . 0 . 152 node-2 ... 10 . 0 . 0 . 155 node-5
You will now be able to do a nslookup on the hostnames of the cluster nodes. Bear in mind that a ping will also resolve the hostname but will not reply successfully because of the lack of proper routing to the cluster nodes.
Install and configure FoxyProxy
Use the Firefox extensions installer or go to https://getfoxyproxy.org/ to download the extension. I used the Basic version, which has enough functionality to support this use case. You may configure it like the picture below:
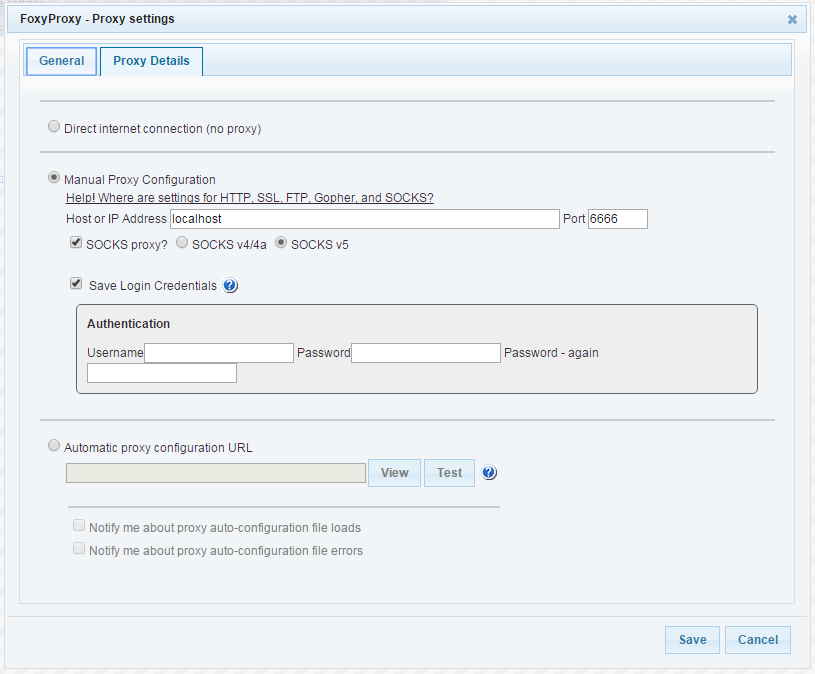
The important bits here are to make sure you check the ‘SOCKS proxy?’ box and ‘SOCKS v5’ bullet. The host or IP address is ‘localhost’ and the port set to any underprivileged one, like 6666 in my case. Remember this number because it is needed when the connection to the cluster is made. FoxyProxy will look like below. Please note that once you enable FoxyProxy in this scenario, you are not able to browse other websites, it will be a dedicated connection to the cluster! So enable and disable FoxyProxy to your needs.

Connect to the cluster
Connecting to the cluster involves two steps: connecting to the Stepping Server followed by connecting to any one of the cluster-nodes.
While connecting to the Stepping Server it is important that a few configurations are made:
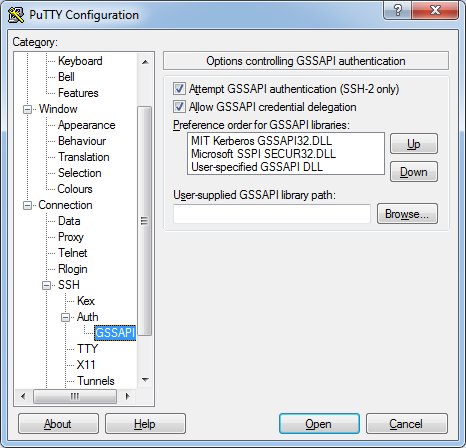
1 – In PuTTY you will need ‘Allow GSSAPI credential delegation’ to be able to take the Kerberos ticket with you all the way down to the cluster-nodes.
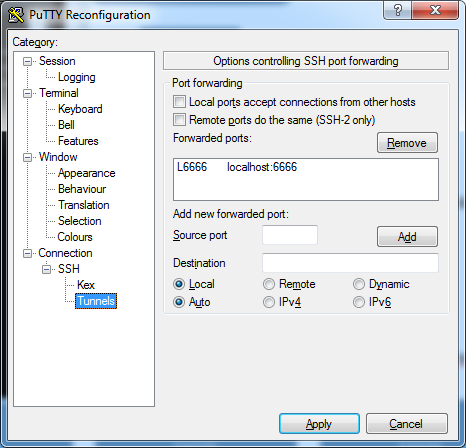
2 – In PuTTY’s tunnel configuration add a local forward from the FoxyProxy port (6666) to localhost:6666. ‘Localhost’ in this case refers to the Stepping Server, not your workstation!
3 – Do NOT check ‘Local ports accept connections from other hosts’. If you do that and you have no firewall installed, other users are able to use your workstation as a gateway to the cluster!
Setting GSSAPI options
Setting up port forwarding
After a successful connection to the Stepping Server you are now ready to continue to on of the cluster nodes. On our Linux host it proved to be enough to enter
ssh -D 6666 node-1
The magic is hidden in the -D command-line switch. This starts a dynamic proxy on the connection which is able to forward requests on ANY node/port combination. FoxyProxy sends it’s requests via the PuTTY connection and the Linux ssh connection above to the corresponding server and passes the results back again. I had to keep this connection alive by using a command like ‘ping -i 10 localhost’ because it looked like IT disabled connection keep-alives in SSHD. The chain now looks like this:
![]()
Voilà
The end result should be that you are now able to browse to the various web ui’s of your cluster:
1 – Kibana : http://node-1:5601/app/kibana#/dashboard/cluster
2 – HUE : http://node-2:8888/jobbrowser/
3 – HDFS : http://node-3:50070/explorer.html#/
4 – YARN : http://node-4:8088/cluster/nodes
Note the use of the hostnames of the cluster and the ability to actually use ANY port on the cluster nodes. This HIGHLY differs from a scenario where you do local port forwarding. When browsing YARN, for instance, you are now able to connect to any node, to any port/service of YARN like the 8042 node HTTP port, making the cluster easily browsable.
Conclusion
At first glance, I just shook my head and wondered why things could be overcomplicated and secured so/too much. But as with any client, there is a reason for most aspects of security. In the end I managed to satisfy the need to connect to the web ui’s of the cluster in a legal, secure and maintainable way.
After finding this one out, other users of the cluster were able to connect as well and do their magic. Next stop, of course: submitting a Spark job using the proxy!
Heading picture re-used from : http://neurosciencenews.com/neuron-cluster-mapping-neuroscience-1807